
为不确定性建立秩序:LLM API 网关的设计与实现
Published:
LLM API 网关不是“把几个模型接口包一层”这么简单。对 AI-native 产品来说,它更像一层执行控制面:在 MaaS(Model-as-a-Service)、对象存储、任务状态机、内容安全、成本统计和合规审计之间建立秩序。本文从一个 AI 漫画平台的自建 LLMAPI 模块实践出发,讨论为什么通用聚合层还不够、媒体生成任务会怎样放大网关价值,以及以后面向国内小微团队的低门槛大模型网关可能长成什么样🤔。
摘要 🧭
这篇文章有两条线索。
一条是工程线:某 AI 产品的 llmapi 模块面对多家 provider、多种模态、多种执行路径和越来越多的合规要求,最终选择自建网关,并逐步搭出一套包含任务状态机、资源持久化、key 运行时治理、日志审计和调用统计的系统。
另一条是商业线:LLM API 接入正在从“调模型”变成“管理不确定的智能执行”。模型能力、价格、限流、地区、内容安全、数据出境、审计留痕都会变化。对 AI-native 产品来说,网关不只是技术中间件,而是把 MaaS、模型供应商、业务资产和合规证据接到一起的控制面。
核心结论很简单:通用 LLM 聚合层已经有价值,但在国内小微团队、媒体生成任务和合规友好自托管场景里,仍然存在一个没有被完全填上的位置。
一、这不是新问题:同构困境反复出现 🔌
每当一批新的后端服务涌现,总会出现同一个问题:N 个服务各有各的协议,业务系统不可能为每一个单独适配,于是需要一个中间层统一接入。
ESB 时代:企业内部的 ERP、CRM、OA、财务系统有不同协议和数据格式,Enterprise Service Bus 用 XML、SOAP、消息队列把它们串起来。它解决了连接问题,也带来了重量级配置和长期技术债。
API 网关时代:微服务之后,Kong、APISIX、Nginx Plus、AWS API Gateway 这一代基础设施把重点放到路由、认证、限流和观测。
LLM API 网关时代:现在的问题又变了一层。OpenAI、Anthropic、阿里云百炼、火山方舟、MiniMax、Google AI、各类 MaaS 和聚合平台都在快速变化。文本、图像、视频、音频、CV 服务的协议不同;同步返回、流式返回、提交任务后轮询的生命周期也不同。LiteLLM、OpenRouter、Portkey、Higress 等工具已经说明这个市场真实存在,但它们的侧重点不同:有的偏 OpenAI 兼容代理,有的偏 provider routing,有的偏企业治理和 guardrails,有的偏云原生网关插件化。1234
历史规律很清楚:新的后端生态爆发之后,中间层会从“能接入”走向“可运维”,再走向“可审计”。LLM API 这条线正在这个过程中。
二、市场现状:AI-native 产品需要新的控制面 📈
市场上的 LLM 接入方案可以粗略分成四层:
| 层级 | 定位 | 典型形态 | 核心价值 |
|---|---|---|---|
| L0 | 模型与推理执行层 | OpenAI、Claude、Gemini、Qwen、DeepSeek、Llama、vLLM、SGLang、TGI | 产出 token、图片、视频、音频或分析结果 |
| L1 | API 聚合层 | LiteLLM1、OpenRouter2、One API5、Evolink6 | 统一接口、模型路由、fallback、key 管理 |
| L2 | 网关治理层 | Portkey3、Higress4、APIPark7、Cloudflare AI Gateway8、Kong AI Gateway9、Envoy AI Gateway10 | 预算、限流、观测、guardrails、插件治理 |
| L3 | 业务资产与合规层 | 自建或深度定制 | 任务状态机、资源入库、内容审核、审计证据、业务权限 |
AI 投入已经从“尝鲜”进入“规模化但仍不稳定”的阶段。Stanford AI Index 记录到生成式 AI 私人投资持续增长;McKinsey 2025 年调研也显示企业正在从试点走向 agentic AI 实验和局部扩展,但真正把价值吃下来的公司仍是少数。1112 Gartner 对 agentic AI 的判断更冷静:一边预测企业软件会快速加入 agentic 能力,一边提醒大量项目会因为 ROI、风险控制和产品包装不清而取消。13
这对 LLMAPI 网关的启发是:未来的瓶颈不只是“有没有模型可用”,而是“能不能把模型调用变成可治理、可追踪、可计费、可复盘的业务执行”。MaaS 会继续降低算力和模型门槛,但它也会把 provider 波动、区域合规、价格策略和结果持久化问题留给上层系统。
模型层本身也在分化:闭源 API 模型继续提供最高上限和多模态产品化能力,OpenAI、Claude、Gemini 这类模型族持续强化工具调用、长上下文、音视频和 agent 能力;开源或开放权重模型则让私有化、低成本和可控部署变得现实,Qwen、DeepSeek、Llama、Mistral 等生态正在快速成熟。与此同时,vLLM、SGLang、TensorRT-LLM、TGI、Ollama、llama.cpp 这类推理框架把自托管推理从“能跑”推向“可服务化”。141516171819 这意味着 LLMAPI 网关不能只假设“上游是一个 OpenAI 兼容接口”,而要准备面对闭源 API、国产云、聚合商、自托管推理、离线模型和多模态专用模型的混合运行。
研究脉络也在把网关推向更厚的一层:RAG 把外部知识和资源引用接进模型上下文,ReAct、Toolformer、Gorilla 把模型调用工具和 API 变成主流范式,FrugalGPT 与 RouteLLM 证明“按任务路由模型”可以同时影响成本和质量,vLLM、SGLang、FlashAttention、Orca 则说明推理服务本身已经是一门系统工程。20212223242526272829 这些论文不直接等于产品方案,但共同指向一个结论:LLMAPI 网关会从简单 proxy 变成模型、工具、资源、成本和执行状态之间的控制层。

🛜 公开模型厂商通常不披露全球 token 消耗绝对值,所以这张图改用多源综合代理指数:把 Anthropic Claude.ai usage_count、World Bank 对 GenAI 工具流量的研究、Microsoft AI Diffusion、CNNIC 中国 AI 产品用户规模、Stanford AI Index / Global AI Vibrancy、WIPO GenAI 专利格局、Oxford AI readiness 与 ITU 连接度一起校正。它的用途是判断 LLMAPI 网关要服务哪些区域变量,不是把指数换算成真实 token 账单。支撑材料可直接打开:指数 CSV、来源清单、PDF 简报。30
三、监管正在改变网关的职责 ⚖️
国内 AI 产品的合规要求不是一个单点动作,而是一条链。
底座是《网络安全法》《数据安全法》《个人信息保护法》。它们决定了数据安全、个人信息处理、重要数据和跨境流动的基本边界。313233 在 AI 应用层,《生成式人工智能服务管理暂行办法》要求提供生成式 AI 服务时关注安全、真实、合法、权益保护和生成内容标识;《互联网信息服务算法推荐管理规定》要求算法备案、内容治理、用户权益保护和算法透明;《互联网信息服务深度合成管理规定》覆盖文本、语音、图像、视频等深度合成服务,并要求对虚假信息风险、备案和标识进行管理。343536 2025 年发布并施行的《人工智能生成合成内容标识办法》进一步把显式标识、隐式标识、平台提示和元数据要求推到更具体的位置。37
跨境调用也不能简单写成“能访问就能用”。《促进和规范数据跨境流动规定》在放宽部分场景的同时,仍保留了安全评估、个人信息出境标准合同、个人信息保护认证等制度衔接。38 对一个国内 AI 产品来说,调用境外 provider 时,网关至少要知道:payload 里有没有个人信息,是否需要脱敏,能否路由到本地或零留存端点,日志中保留什么,保留多久,谁能访问。
国外监管的共同方向也类似。欧盟 AI Act 用风险分级和 GPAI 义务管理 AI 系统与通用模型;GDPR 对个人数据处理和自动化决策有长期约束。3940 美国目前更偏分散治理:NIST AI RMF 是自愿性风险管理框架,FTC 则用消费者保护和反欺诈执法处理夸大 AI 能力、误导用户等问题,加州也已经通过 AI 生成内容透明度相关立法。414243
这些规定并不要求所有团队都立刻做一个复杂治理平台,但它们共同指向同一件事:AI-native 产品需要把“调用模型”变成“带证据链的执行”。网关层天然适合承接这件事,因为它位于 payload、provider、结果、用户和业务系统之间。
四、第三方方案的结构性边界 🧩
这里不是说现有方案不好。相反,它们证明了 LLM 网关市场已经成立。
LiteLLM 的优势在于 OpenAI 兼容接口、虚拟 key、预算、路由和成本追踪,适合快速把多个文本模型接成统一入口。1 OpenRouter 的 provider routing、fallback、参数匹配、数据留存偏好和 ZDR 路由,让“同一个模型背后有多个供应商”这件事更可控。2 Portkey、Higress、APIPark 更靠近生产治理,强调 guardrails、fallback、负载均衡、预算、限流、语义缓存、观测和插件体系。347 Cloudflare、Kong、Envoy 这类网关体系也在向 AI Gateway 演进,说明传统 API 网关厂商已经把模型流量当成新一代网关场景。8910
国内生态也不是空白。阿里系的 Higress 已经把 AI Gateway 作为开源和商业化并行的方向;腾讯云也在云原生智能网关、AI Agent 安全网关里提供模型 API、MCP 工具和多 agent 治理能力,但从官方资料看,它更像云产品能力而不是一个可以直接拿来二次开发的开源 LLM 网关。44445 这说明“有没有同类产品”不是问题,真正要比较的是部署门槛、业务资产收口、国内合规默认项、媒体任务生命周期,以及它是不是适合小团队长期自托管。
参考 APIPark 系列文章,它们已经把“为什么企业需要 LLM 网关”讲到可理解的程度;但站在 AI-native 产品实践里,更值得比较的是:谁解决统一入口,谁解决生产治理,谁接近媒体资产和 agent 工具链,谁适合小团队低门槛自托管。46 下面这个表按公开仓库和文档做一个近似快照,Stars 会波动,只能当生态热度的弱信号。📄
| 产品 | 层级 | 部署 | 核心能力 | 多模态 / Agent | Stars / 协议 |
|---|---|---|---|---|---|
| LiteLLM47 | L1/L2 | SDK、Proxy、Docker、Helm | 多 provider、virtual key、budget、fallback | 图像/音频/A2A | 约 48.2k / MIT |
| One API5 | L1 | Binary、Docker、宝塔 | 渠道、令牌、额度、倍率、分组 | 文本/绘图 | 约 34.2k / MIT |
| New API4849 | L1/L2 | Docker、宝塔 | 格式转换、计费、重试、限流 | 图像/音频/视频 | 约 31.6k / AGPL-3.0 |
| Portkey50 | L2 | npx、自托管、托管版 | guardrails、routing、cache、observability | 语言/视觉/音频/图像 | 约 11.7k / MIT |
| Higress4 | L2 | Docker、Helm、K8s | 协议转换、语义缓存、限流、插件 | AI Gateway + MCP | 约 8.3k / Apache-2.0 |
| Bifrost51 | L2 | npx、Docker、Go SDK、Helm | 高性能、fallback、budget、MCP | text/images/audio | 约 5.2k / Apache-2.0 |
| APIPark7 | L2/API 平台 | 一键脚本、容器化 | API 门户、审批、统计、多模型灾备 | Prompt API 化 | 约 1.7k / Apache-2.0 |
| APISIX52 | L2 通用网关 | Docker、Helm、K8s | ai-proxy、fallback、token 限流 | LLM/embedding | 约 16.6k / Apache-2.0 |
| Envoy AI Gateway10 | L2 云原生 | K8s、Gateway API | 双层网关、全局限流、endpoint picker | LLM/agent 流量 | 约 1.6k / Apache-2.0 |
| Helicone53 | L2/观测 | npx、Docker、托管版 | routing、rate limit、cache、OTel | 100+ models | 约 0.6k / GPL-3.0 |
| Inference Gateway54 | L1/L2 | Script、binary、CLI、K8s | 多 provider、MCP、metrics | vision/tool-use | 约 0.08k / MIT |
| agentgateway55 | Agent 数据面 | standalone、K8s | MCP、A2A、LLM、policy | agent-to-tool | 约 1.4k / Apache-2.0 |
简化后可以看出三类位置:LiteLLM、One API、New API 更偏统一接入;Portkey、Higress、APIPark、APISIX、Envoy 更偏生产治理;agentgateway 说明下一代网关会同时治理模型、agent 与工具连接。
从这个横向比较看,当前市场的薄弱处也更清楚:
- 多模态支持经常停在“能调接口”。 图像、音频、视频、CV 的难点不是发一个请求,而是异步任务、临时 URL、base64/binary、子任务聚合、对象存储、权限和后续编辑链路。
- DNS/CDN/边缘基础设施还没有真正和 LLM 网关联动。 现在多数方案按 provider、key、成本、错误率路由;未来也许需要像 DNS + CDN 那样,把地区合规、模型能力、数据驻留、边缘缓存、生成资产分发和故障切换放在同一张路由表里。
- 合规默认项还不够产品化。 很多网关有日志和 guardrails,但数据脱敏、跨境策略、内容标识、留存期限、用户授权、模型备案状态仍需要业务层自己补齐。
- 业务闭环可能继续上移到 L3。 对媒体生成、长任务和 agent 工具链来说,网关只把响应转发回来往往还不够;结果还要进入平台内可权限控制、可审计、可复用的资源体系。
再看 issue,会比官网更接近产品摩擦,但它也只能作为样本证据。这里把 APIPark、LiteLLM、Higress、New API、Portkey、Bifrost、APISIX、Envoy AI Gateway、Helicone、vLLM、SGLang、llama.cpp 中 75 条公开 issue observation 做了一个目的性编码:每条只归入一个主类,保留 secondary tags,用来减少“凭直觉下结论”的风险。565758596061626364

📄 样本不随机,不能代表全部市场;它更适合用来识别工程摩擦的类型。图里的 L3 相关性 不是网络 OSI 三层,而是指 issue 是否触及本文的 L3“业务资产与合规层”:资源持久化、权限、审计证据、长期日志、成本账单、对象存储/CDN 或 policy。完整数据可直接打开:样本编码 CSV、分类计数 CSV、能力归属 CSV、论文附录式 PDF。
这组样本中,最密集的问题不是“多接几个模型”,而是 provider adapter/schema、流式协议一致性、agent/tool 状态、部署运维、日志成本和可靠性治理。更稳妥的表述是:provider adapter、参数 schema、OpenAPI/MCP 包、smoke case、部署 recipe 和复现模板适合 build in community;托管对象存储/CDN、provider 健康探测、合规策略包、长期日志归档、成本账单、SLA 和企业支持更偏平台自运营。
对媒体生成类产品,还会多出一类在通用 L1/L2 里不一定优先解决的问题:provider 返回的是临时 URL、base64、二进制、轮询任务结果或多子任务聚合结果。业务侧需要的往往不是临时链接,而是平台内稳定的 resource_id、对象存储 key、权限、审计记录和后续可编辑资产。因此,通用 L1/L2 网关可以作为入口或参考;当产品进入图像、视频、音频、CV 和 agent 工作流时,L3 资源化与证据链会更像一层必要补充,而不是一开始就必须重做整个网关。
五、为什么要自建 🛠️
结合当前代码现实,自建理由可以更准确地写成这样:
| 需求 | 当前系统状态 | 现成 L1/L2 是否足够 |
|---|---|---|
submit_poll 生命周期 | 已实现平台 task_id 与 provider_task_id 的状态机、轮询、终态聚合 | 通常不够,需要业务层补 |
| 媒体结果资源化 | 已实现远程 URL/base64/bytes 到 S3 兼容存储和 resources 表 | 通常不管平台资产入库 |
| 多模态同构 | 已接入文本、图像、视频、音频、CV、视频分析等 adapter,但覆盖和编排仍在扩展 | 通常只覆盖部分模态 |
| 文本流式 | 已有 stream_chat() 直连路径,返回 OpenAI Chat Completions chunk | 通用方案可覆盖,但要接入本地审计 |
| key 运行时治理 | 已有 disabled、cooldown、inflight、task-key 绑定 | 通用方案有类似能力,但难贴业务 |
| 合规审计 | 已有 runtime、audit、payload、error 分层日志 | 还缺内容审核策略、脱敏规则、留存策略产品化 |
| 动态能力注册 | ModelTypeDefinition 仍偏静态 | 需要后续框架改造 |
所以自建不是因为市场上没有工具,而是因为业务边界超过了“LLM API 代理”。系统需要的是:统一调用入口、provider 参数保真、异步任务生命周期、资源持久化、审计证据、统计口径和国内 provider 优先适配。
六、实现方式 ⚙️
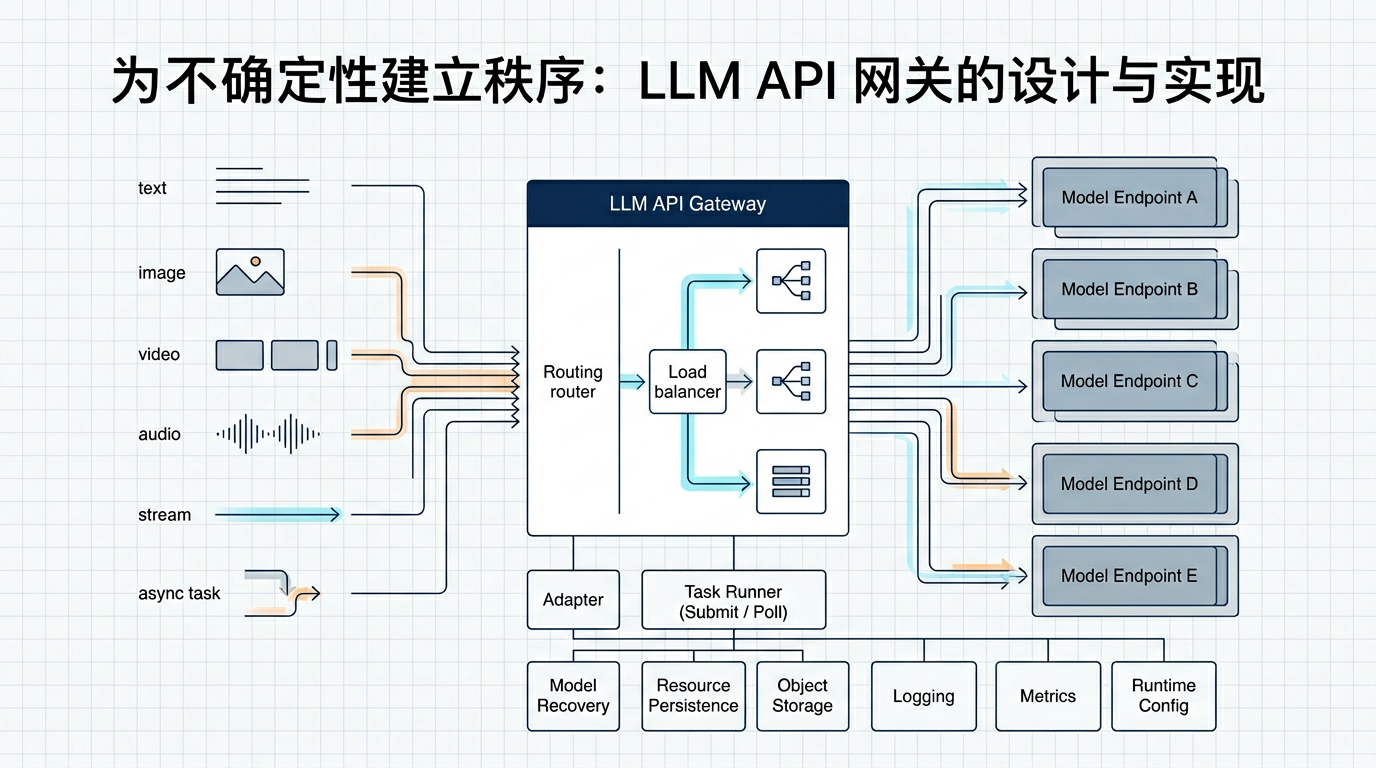
整体分层
业务代码
↓
Client API 统一调用入口,业务只传 model_id + params
↓
Runtime Config 从 DB 加载模型实例、key、URL 等,Redis 缓存热状态
↓
Adapter 协议翻译、参数校验、provider 请求/响应映射、状态归一
↓
Task Runner 批任务提交、轮询、终态收敛、结果聚合
↓
Resource Service 下载 provider 临时文件、上传 S3、写库、产出 resource_id
↓
Logging / Audit runtime / audit / payload / error 分层日志

LLMAPI 的价值不只在“转发请求”,而是在模型路由、任务状态、资源入库、审计和统计之间形成一个执行控制面。
参数分层:__llmapi 与 __model
调用参数拆成两块:
params.__llmapi:平台统一语义,包含inputs、control、adaptparams.__model:provider 原生参数,由 adapter 保真处理
adapt 层处理“业务意图明确,但各家 provider 表达不一致”的参数。negative_prompt 就是典型例子:有的 provider 有原生字段,有的要合并进 prompt,有的不支持。adapter 按 provider 能力决定映射方式,调用方不需要知道细节。
两种批任务执行模式 + 一条流式路径
request_response 一次请求直接返回结果,适合文本、同步图像、CV
submit_poll 提交任务拿 provider_task_id,之后轮询到终态,适合视频、音频、异步图像
stream_chat 文本流式直连路径,不进入批任务状态机,输出 ChatCompletionChunk
代码层面 ExecutionMode 只有 request_response 和 submit_poll。stream_chat() 是独立的文本流式入口,会在当前 API 进程里直接消费 provider 流,并在 llmapi 边界统一成 OpenAI Chat Completions chunk。
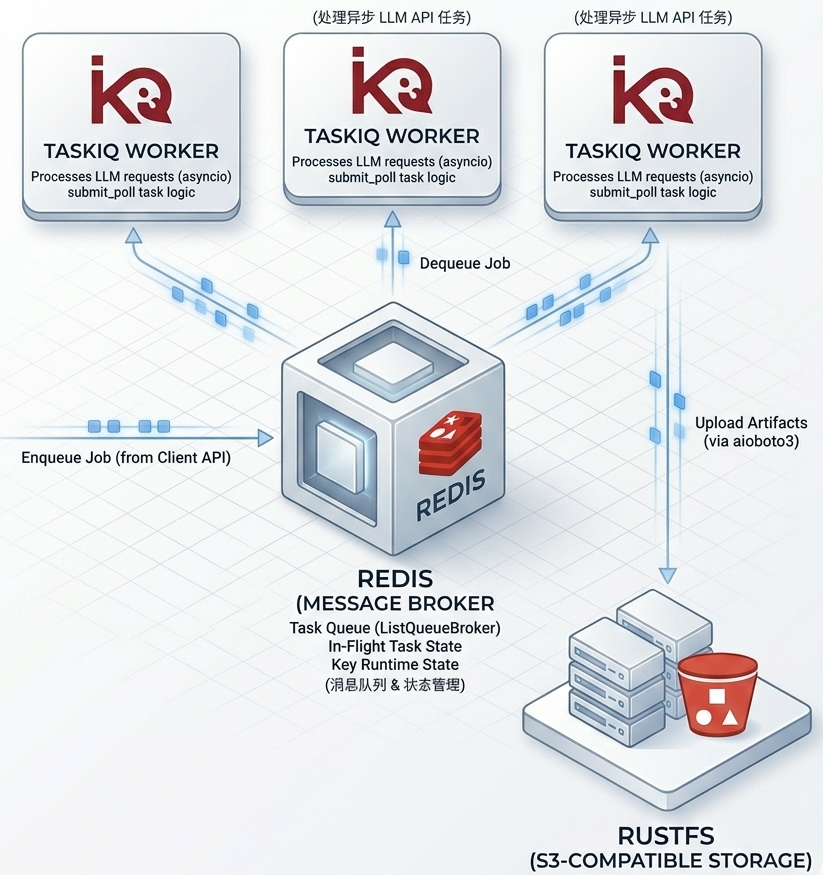
任务调度:TaskIQ + Redis + asyncio
批任务通过 TaskIQ 分发,底层使用 Redis ListQueueBroker。LLMAPI 有独立于主应用的 broker,worker 可以单独部署和扩容。系统支持两种 dispatch 模式:
taskiq:任务进入 Redis 队列,由独立 worker 消费,适合生产环境local:用asyncio.create_task在当前进程内直接执行,适合开发调试
并发主要靠 asyncio。例如请求 8 张图而 provider 单次限制 4 张时,系统会拆成多个子请求并发提交,再聚合结果;submit_poll 的多个子任务轮询也可以并行推进。
HTTP 与 SDK 边界
大多数 provider HTTP 请求走 HTTPTool 和共享的 httpx.AsyncClient 连接池,按 origin 复用客户端实例,配置连接数、keepalive、HTTP/2 和重试策略。文本流式模型如果是 OpenAI-compatible,也可以直接使用 openai.AsyncOpenAI;框架要求 adapter 在 llmapi 边界返回统一事件和 ChatCompletionChunk,而不是把 provider 私有流格式泄漏给调用方。
状态管理:Redis
Redis 承担三个角色:
- 任务热状态:
BatchTaskState存 Redis,包含status / provider_task_id / progress / result_ref / resource_ids - key 运行时状态:
disabled / cooldown / inflight跨 worker 共享,提交后绑定task_id -> key_id - 运行时配置缓存:模型配置从 PostgreSQL 加载后写 Redis,TTL 默认 300 秒
资源持久化:aioboto3 + S3 兼容对象存储
provider 临时 URL / base64 / bytes
→ httpx 下载或云端 fetch
→ aioboto3 上传到 S3 兼容对象存储
→ 写入 resources 表
→ 返回平台 resource_id
当前代码面向 S3 兼容后端,既可以接 RustFS,也可以接 MinIO、七牛 S3 等实现。这个设计的关键不是某个存储品牌,而是业务结果不再停留在 provider 临时 URL 上。
日志与审计
logs/llmapi/{date}/
├── runtime/ 运行时日志
├── audit/ 任务生命周期事件
├── payload/ 请求与结果 payload 摘要
└── error/ 详细错误记录
每个关键节点记录 request_id / trace_id / task_id / provider_task_id / key_id / latency_ms 等信息。submit_poll 进度变化达到阈值时会单独写轮询事件,方便回放任务生命周期。
七、还不够好的地方 🧪
provider 变更管理还不系统。 各家 provider 字段、状态码、限流策略和返回结构变化很快,目前主要靠人工跟进。更理想的方式是对 OpenAPI schema、官方文档、真实 smoke 结果做差异检测。
真实 provider 回归还没有持续化。 仓库里已经有 real_env_smoke.py、real_dashscope_smoke.py、real_dashscope_official_smoke.py 等脚本,但还没有稳定纳入 CI、定时任务和告警。
模型能力注册仍偏静态。 ModelTypeDefinition、input_types、parameter_schema、shared_input_schema 主要由 adapter 代码声明。新增模型仍需要代码发布,后续应走向“代码 adapter + 数据库能力配置”的混合模式。
非 LLM 模态已经开始同构,但还没有产品化。 火山 CV 分割、全妙视频分析、音频、视频、图像类 adapter 已经进入框架,但内容审核、裁剪、打水印、OCR、人脸检测、字幕和 agent 编排还需要继续收口。
合规策略还不是 policy-as-code。 现在有审计日志和 payload 摘要,但内容安全审核节点、脱敏规则、数据留存期限、跨境路由规则、用户授权记录还需要配置化。
统计和主链路仍有耦合。 调用统计在终态路径写入,后续可以改为 Redis Streams、Kafka 或 ClickHouse 管道,把任务成功率、平均延迟、provider 错误分布、成本分布做成实时面板。
八、展望:MaaS 与 LLMAPI 网关会走向哪里 🔭
未来的 LLMAPI 网关更接近 AI-native 产品的控制面,而不是传统意义上的代理。
参考阿里云《AI 原生应用架构白皮书》的产业侧归纳,AI 原生应用已经不只是“模型 + prompt”,而是模型、Agent、RAG、记忆、工具、网关、运行时、可观测、评估和安全的组合系统。65 结合上面的论文线索,可以给出一个更贴近大模型网关的前瞻观察:短期看统一接入和成本治理,中期看工具/MCP、RAG 资源层和多模态资产沉淀,长期看合规、评估、安全和多 agent 运行时会逐步进入同一个控制面。这个过程不会一夜完成,但方向上更像“AI-native 中间件”,而不是传统 API gateway 的小修小补。
第一,MaaS 会商品化,但调用治理不会商品化。 模型和推理资源会越来越像云计算里的算力实例,价格下降、可替换性上升。但真正困难的是动态选择:哪次请求该走哪个 provider,是否需要零留存,是否允许境外端点,失败后能不能 fallback,结果是否已经落库,成本是否超预算。
第二,网关的合约会从 API contract 升级为 execution contract。 过去的 API 网关关心路径、鉴权和限流;LLMAPI 网关还要关心 prompt、输入资源、输出资源、任务状态、内容安全、审计证据和人类复核点。它管理的不是一次 HTTP 请求,而是一段不确定执行。
第三,基于国内云产品、开源网关和小团队约束的观察,“低门槛自托管 + 合规默认打开”可能是一个有价值的位置。 大公司可以自建,中型团队会在开源和托管之间摇摆,小微团队更容易卡在部署、provider 适配、内容审核和资源落库这些琐碎但绕不开的地方。一个能在普通云服务器上跑起来的方案,未必需要一开始就很大,但至少应该把 Redis、PostgreSQL、S3 兼容对象存储、worker、Web 控制台、国内 provider adapter、合规日志和内容审核 hook 串起来。
第四,agent 会放大网关价值。 单次问答时代,网关只是模型代理;agent 时代,一次用户请求会触发搜索、读文件、生成图、生成视频、审核、裁剪、发布、回滚等多步动作。没有统一任务状态、资源引用和审计链路,agent 系统很快会变成难以复盘的黑箱。
第五,真正的壁垒不在“兼容更多模型”,而在“把结果变成资产”。 兼容 provider 很重要,但长期壁垒会出现在资源持久化、权限体系、业务状态机、合规证据、成本分析和用户工作流上。谁能把一次不确定的 AI 调用变成稳定、可追踪、可运营的业务对象,谁就更接近 AI-native 基础设施。
第六,网关也要变成“模型喜欢调用的库”。 下一代入口也许不一定先是一个复杂控制台,而可以很简单:一个 CLI、一个 npm package、一个 SDK、一个 MCP tool 或一份清晰的 OpenAPI schema。大道至简:一键启动、稳定参数、明确错误码、幂等任务、可复用 resource_id。对 agent 来说,这比花哨界面更重要;对长上下文和多模态模型来说,把图片、视频、音频、PDF 和中间结果沉淀到对象存储 + CDN,再用短引用回填上下文,本质上是在给小平台补一层持久化记忆。
第七,安全高防适合平台侧,但不一定是第一战场。 OWASP LLM Top 10 已经把 prompt injection、敏感信息泄露、模型 DoS、不安全插件、过度代理等列为核心风险。66 对 LLMAPI 网关来说,IP 滥用、刷量、prompt 注入、tool 越权、MCP server 滥接、多租户 key 泄漏和成本打爆,都比普通 API 更贵。限流、配额、WAF、prompt guard、租户隔离、审计和异常熔断天然适合云原生平台侧做,而不是让每个用户在业务代码里重复集成。Cloudflare、Kong 这类 AI Gateway 已经把 rate limiting、prompt guard、语义缓存和流量治理放进网关能力里。6768 更远一点,PSI 可以用于跨租户风险指纹、违规素材哈希或黑名单集合的隐私保护匹配,让平台判断“是否命中风险集”而不暴露完整集合。69 但这只是一个可选方向:如果真实滥用还没出现,过早堆安全军备会拖慢产品。平台侧更好的节奏是先把权限、限流、审计、隔离做好,等攻击面被市场验证后再补强,不剑走偏锋。
安全研究还提示了另一条边界:prompt injection 和 agent 越权并不是“提示词写好一点”就能彻底解决的问题。间接提示注入、工具调用链路污染、反思式 agent 的自我修正失败,都要求网关在工具权限、上下文来源、输出落库和人类复核点上保留硬边界。707172 这也是为什么安全能力适合平台侧内置,但不宜喧宾夺主。
九、一个人能做什么 🌱
大四毕业,考研备考那一年基本没怎么写代码,现在还要同时处理课程、打游戏、解决毕业问题、旅游、实验室杂活和其他事情。重新上手这个项目时,一边补课一边做,很多坑也暴露了这个领域可能会让小团队卡住的位置。
回到工程实践本身,这个领域真正缺的大概不会是另一个 LiteLLM 或另一个 Portkey,而是一个面向团队和个人开发者的、合规友好的、低门槛自托管,或者至少能被小团队低成本托管和二次开发的 LLMAPI 网关。
它的初版也许可以很朴素:
- Docker Compose / CLI / npm package 一键启动,不强依赖 Kubernetes
- 提供 SDK、MCP tool 或 OpenAPI schema,让模型和 agent 稳定调用
- 文本、图像、视频、音频、CV 服务走同一套
model_id + params submit_poll生命周期、资源持久化、key 管理、审计日志默认内置- 可选托管对象存储和 CDN,把多模态结果、长上下文材料和中间产物转成长期可引用的
resource_id - 基础安全包内置:租户级限流、预算熔断、key 隔离、prompt/tool guard hook 和审计留痕
- 国内 provider 优先适配,境外 provider 通过路由和脱敏策略接入
- 提供一个简单控制台,看 key、成本、错误率、任务状态和资源结果
这不是一个宏大的产品愿景,而是一个可以从工程实践里慢慢长出来的方向。很多小平台未必会自己维护复杂会话、资源归档和 CDN 分发,但它们会需要一层能把模型、资源、合规和业务动作编排在一起的基础设施。LLMAPI 网关正好站在这个位置。☁️

往者不可谏,来者犹可追!本科四年辛苦啦老己,毕业快乐🎓!
参考资料 📚
LiteLLM Documentation。LiteLLM 文档介绍其 Proxy Server、虚拟 key、预算、负载均衡和成本追踪等能力,适合作为 OpenAI-compatible 聚合层参考。 ↩ ↩2 ↩3
OpenRouter Provider Routing Documentation。OpenRouter 文档说明 provider routing、fallback、参数匹配、数据留存偏好和 ZDR 路由等机制。 ↩ ↩2 ↩3
Portkey AI Gateway Documentation。Portkey 文档列出 universal API、guardrails、fallback、负载均衡、预算、限流、缓存和观测能力。 ↩ ↩2 ↩3
Higress AI Gateway。Higress 官方页面介绍多模型统一路由、协议转换、语义缓存、token 级限流、内容安全、认证、观测、fallback 和插件化能力。 ↩ ↩2 ↩3 ↩4 ↩5
One API GitHub Repository。One API 是开源的 LLM API 管理与分发系统,用于统一多 provider 接入、key 管理和二次分发。 ↩ ↩2
EvoLink Documentation。EvoLink 定位为企业 AI gateway / 统一模型访问层,覆盖文本、图像、视频、音频模型接入、任务管理和用量追踪。 ↩
APIPark GitHub Repository。APIPark 是开源 AI/API 网关和开发者门户,支持统一 API、LLM API 管理、分发、审批、统计、负载均衡和多模型灾备。 ↩ ↩2 ↩3
Cloudflare AI Gateway Documentation。Cloudflare AI Gateway 提供模型请求观测、缓存、限流、日志和多 provider 接入能力。 ↩ ↩2
Kong AI Gateway Documentation。Kong 将模型路由、prompt guard、认证、限流和 AI 插件纳入 API 网关体系。 ↩ ↩2
Envoy AI Gateway。Envoy AI Gateway 是面向 LLM 和 agent 流量的 Envoy 网关项目,强调统一路由、策略和可观测性。 ↩ ↩2 ↩3
Stanford HAI, The 2025 AI Index Report。AI Index 对模型、投资、产业采用、政策等指标做年度追踪,其中经济章节记录生成式 AI 投资增长。 ↩
McKinsey, The State of AI: Global Survey 2025。McKinsey 2025 年调研讨论企业 AI 采用、agentic AI 试验、规模化难点和组织转型。 ↩
Gartner, Agentic AI Projects Prediction, 2025。Gartner 预测大量 agentic AI 项目会因 ROI、风险控制和过度包装等原因被取消,同时企业软件中的 agentic 能力会快速增加。 ↩
vLLM GitHub Repository。vLLM 是高吞吐 LLM serving 框架,常用于自托管开源模型和兼容 OpenAI API 的推理服务。 ↩
SGLang GitHub Repository。SGLang 面向 LLM 和 VLM 的高性能 serving 与结构化生成场景。 ↩
NVIDIA TensorRT-LLM GitHub Repository。TensorRT-LLM 提供面向 NVIDIA GPU 的 LLM 优化、部署和推理加速能力。 ↩
Hugging Face Text Generation Inference GitHub Repository。TGI 是 Hugging Face 的生产级文本生成推理服务。 ↩
Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” NeurIPS 2020。RAG 将检索和生成结合,是把外部知识、文件和资源引用接入模型上下文的基础论文之一。 ↩
Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” ICLR 2023。ReAct 将 reasoning trace 与 action 交织,推动了模型调用外部工具和环境反馈的 agent 范式。 ↩
Schick et al., “Toolformer: Language Models Can Teach Themselves to Use Tools,” NeurIPS 2023。Toolformer 展示模型可以学习何时调用搜索、计算器、翻译等工具,说明工具调用会成为模型接口的一部分。 ↩
Patil et al., “Gorilla: Large Language Model Connected with Massive APIs,” 2023。Gorilla 聚焦 LLM 调用大量 API 的能力,对 LLMAPI 网关的接口描述、参数保真和工具注册有直接参考价值。 ↩
Chen et al., “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance,” 2023。FrugalGPT 讨论用级联和路由策略降低 LLM 使用成本,是模型路由和成本治理的重要论文。 ↩
Ong et al., “RouteLLM: Learning to Route LLMs with Preference Data,” 2024。RouteLLM 研究如何根据偏好数据进行模型路由,支撑“网关按任务选择模型”的方向。 ↩
Kwon et al., “Efficient Memory Management for Large Language Model Serving with PagedAttention,” SOSP 2023。vLLM / PagedAttention 论文说明推理服务的吞吐、显存和调度本身就是系统工程。 ↩
Zheng et al., “SGLang: Efficient Execution of Structured Language Model Programs,” 2023。SGLang 关注结构化语言模型程序的高效执行,对 agent、工具调用和复杂推理工作流有参考意义。 ↩
Dao et al., “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,” NeurIPS 2022。FlashAttention 代表长上下文和高效推理背后的底层系统优化方向。 ↩
Yu et al., “Orca: A Distributed Serving System for Transformer-Based Generative Models,” OSDI 2022。Orca 讨论生成式 Transformer 模型的分布式 serving 系统,对批处理、调度和推理服务架构有参考价值。 ↩
全球 LLM 区域需求图使用的是多源综合代理,而非 token 消耗真值。公开可得来源包括 Anthropic Economic Index Dataset、World Bank《Who on Earth Is Using Generative AI?》、World Bank reproducibility package、Microsoft Global AI Adoption 2025、CNNIC / 国务院英文摘要、WIPO Generative AI Patent Landscape Report、Stanford 2025 AI Index、Stanford Global AI Vibrancy Tool、Oxford Government AI Readiness Index 与 ITU Facts and Figures 2025。支撑文件包括:指数 CSV、来源清单、研究简报 MD、研究简报 PDF。 ↩
《中华人民共和国网络安全法》。网络安全法是国内网络运行、信息安全、违法信息处置和关键基础设施保护的重要基础。 ↩
《中华人民共和国数据安全法》。数据安全法确立数据分类分级、重要数据、数据出境和数据处理安全等基础制度。 ↩
《中华人民共和国个人信息保护法》。个人信息保护法规定个人信息处理、告知同意、敏感个人信息、自动化决策和跨境提供等规则。 ↩
《生成式人工智能服务管理暂行办法》。该办法自 2023 年 8 月 15 日起施行,是国内生成式 AI 服务治理的核心部门规章之一。 ↩
《互联网信息服务算法推荐管理规定》。该规定覆盖算法推荐服务的备案、透明度、内容治理、用户权益保护和反不正当竞争等要求。 ↩
《互联网信息服务深度合成管理规定》。该规定覆盖深度合成服务,强调标识、辟谣、备案和对虚假信息风险的治理。 ↩
《人工智能生成合成内容标识办法》。该办法自 2025 年 9 月 1 日起施行,进一步规范 AI 生成合成内容的显式标识、隐式标识和服务协议提示。 ↩
《促进和规范数据跨境流动规定》。该规定对数据出境安全评估、个人信息出境标准合同、个人信息保护认证和豁免场景做了衔接安排。 ↩
European Commission, General-purpose AI obligations under the AI Act;另见 EUR-Lex Regulation (EU) 2024/1689。欧盟 AI Act 建立风险分级监管框架,并对 GPAI 模型提供者设置透明度和风险管理义务。 ↩
EUR-Lex, GDPR Regulation (EU) 2016/679。GDPR 是欧盟个人数据保护基础法规,对个人数据处理和自动化决策有持续影响。 ↩
NIST AI Risk Management Framework。NIST AI RMF 1.0 是美国重要的自愿性 AI 风险管理框架,2024 年还发布了生成式 AI Profile。 ↩
FTC, Operation AI Comply。FTC 通过消费者保护和反欺诈执法处理夸大 AI 能力、误导用户和不公平行为。 ↩
California SB-942, California AI Transparency Act。该法案要求特定生成式 AI 服务提供者围绕 AI 生成内容提供透明度和披露机制。 ↩
腾讯云云原生智能网关。腾讯云将云原生智能网关定位为 Agent 生态的统一流量控制平面,覆盖大模型调用、MCP 工具调用和多 Agent 协同治理。 ↩
腾讯云 AI Agent 安全网关模型 API 接入。该文档介绍腾讯云 AI Agent 安全网关对模型 API 的集中管控、安全防护、内容安全和第三方/自部署模型接入能力。 ↩
APIPark 博客园 AI 网关相关文章;另见 APIPark 博客园 AI 网关标签页。这些文章适合作为“LLM 网关是什么、企业为什么需要 LLM 网关”的产品科普参照。 ↩
LiteLLM GitHub Repository;另见 LiteLLM LICENSE。LiteLLM 仓库展示其 provider 覆盖、proxy、gateway、MCP、tool calling、observability 等能力,license 文件说明除企业目录外主要使用 MIT。 ↩
New API GitHub Repository。New API 是基于 One API 二次开发的 LLM API 管理与分发系统,强调多模型格式兼容、渠道管理、计费、重试、限流和多模态接口。 ↩
New API Documentation。New API 文档说明部署、模型渠道、计费、令牌、日志和接口兼容等能力。 ↩
Portkey AI Gateway GitHub Repository。Portkey AI Gateway 开源仓库展示其统一模型入口、guardrails、fallback、load balancing、routing、缓存和 observability 能力。 ↩
Bifrost GitHub Repository。Bifrost 是 Go 实现的开源 LLM gateway,强调高吞吐、低延迟、多 provider、fallback、负载均衡、语义缓存、MCP 和多模态支持。 ↩
Apache APISIX GitHub Repository;另见 APISIX
ai-proxy插件文档。APISIX 是云原生 API 网关,ai-proxy等插件把传统 API 网关能力延伸到 LLM 流量治理。 ↩Helicone AI Gateway GitHub Repository。Helicone AI Gateway 强调模型路由、缓存、限流、OpenTelemetry、Helicone 观测集成和本地开发入口。 ↩
Inference Gateway GitHub Repository。Inference Gateway 是轻量级开源 AI gateway,覆盖多 provider 聚合、streaming、tool-use、vision、MCP 和 Prometheus metrics。 ↩
agentgateway GitHub Repository。agentgateway 面向 agent-to-agent、agent-to-tool、MCP、A2A 和 LLM 流量,体现了 agent 网络层治理正在形成独立方向。 ↩
APIPark issue 样本:“离线网络环境下部署失败,无法下载相关镜像”、“希望增加请求日志归档功能”、“本地模型非流式返回为空,流式正常”。这些问题集中暴露了离线部署、日志归档和流式一致性诉求。 ↩
LiteLLM issue 样本:Vercel AI Gateway 流式 reasoning 字段处理、Azure model 缺 base_model 导致 router 崩溃、hosted_vllm 不支持 reasoning_effort。这些问题说明 provider 参数漂移和错误降级是网关核心复杂度。 ↩
Higress issue 样本:agent 透明的上下文压缩与存储、Kubernetes Gateway API 版本兼容问题。这些问题把长上下文外置记忆和云原生兼容性拉到网关设计里。 ↩
New API issue 样本:新增 SiliconFlow channel 后服务 panic。这类问题提示渠道配置、迁移、回滚和故障隔离不能只靠人工排查。 ↩
Portkey AI Gateway issue 列表可见对 thinking、provider 兼容、流式响应和 retry 行为的持续反馈:Portkey-AI/gateway issues。 ↩
Bifrost issue 列表可见 cost 重算、禁用 key、多 backend、homelab 部署和错误信息透出等诉求:maximhq/bifrost issues。 ↩
vLLM issue 样本:Responses API 多模态输入请求、vLLM H1 2026 roadmap / lookahead。这些问题把 MCP、tool calling、parser/renderer、state offload 和多模态 serving 放到同一张技术路线图里。 ↩
SGLang issue 样本:Responses API 缺 custom function tools、OpenAI tool calling / responses API 行为澄清。这些问题说明 OpenAI-compatible 不等于 agent-compatible。 ↩
llama.cpp issue 样本:llama-server tool_calls 参数类型破坏 OpenAI 兼容。本地推理服务也会遇到工具调用字段、JSON schema 和客户端兼容问题。 ↩
阿里云开发者社区,《AI 原生应用架构白皮书》文章页。该文从产业架构角度梳理 AI 原生应用的模型、Agent、RAG、记忆、工具、网关、运行时、可观测、评估与安全等关键要素。 ↩
OWASP Top 10 for Large Language Model Applications。OWASP LLM Top 10 将 prompt injection、敏感信息泄露、供应链风险、数据与模型投毒、模型 DoS、不安全输出处理、过度代理等作为 LLM 应用安全重点。 ↩
Cloudflare AI Gateway Documentation。Cloudflare AI Gateway 文档覆盖模型调用日志、缓存、限流、回退和多 provider 统一治理。 ↩
Kong AI Gateway Documentation。Kong AI Gateway 文档覆盖 prompt guard、LLM 路由、认证、限流、缓存、负载均衡和 AI 插件治理。 ↩
NIST Privacy-Enhancing Cryptography。NIST 将 private set intersection 等隐私增强密码技术作为在不暴露完整数据集合时完成协作计算的方向之一。 ↩
Greshake et al., “Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection,” 2023。该论文展示间接提示注入可以通过外部内容影响 LLM 集成应用,是网关侧工具权限和上下文来源治理的安全依据之一。 ↩
Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning,” NeurIPS 2023。Reflexion 代表 agent 自我反馈和反思式执行方向,也提示 agent 执行链路需要状态、回放和边界控制。 ↩
Wang et al., “A Survey on Large Language Model based Autonomous Agents,” 2023。该综述梳理 LLM agent 的规划、记忆、工具使用和多 agent 协作,为网关与 agent runtime 的边界提供背景。 ↩